
Ein smarter Helpdesk
Generative Künstliche Intelligenz (genKI) hat in die Arbeitswelt längst Einzug gehalten – ob unter Softwareentwicklerinnen, die sich von ChatGPT beim Programmieren helfen lassen, Fachkräften in der Produktion, denen KI-unterstützte Suchmaschinen Lösungen für ihre täglichen Probleme ausgeben oder Designern, die Inspiration in Form KI-generierter Bilder suchen.
Unternehmen stellen diese realweltlichen Entwicklungen vor die unweigerliche Frage, wie sie sich zu genKI-Technologien positionieren und sie für sich nutzbar machen können. Die meisten stehen dabei noch ganz am Anfang, einige haben erste Pilotinitiativen gestartet – doch konkrete Zielstellungen und potenzielle Einsatzszenarien sind oft noch unklar. Zudem gibt es in vielen Unternehmen ethische und rechtliche Bedenken und berechtigte Fragen zu Datenschutz, Urheberrecht und Schutz des geistigen Eigentums.
Forschende des IWF der TU Berlin und des Fraunhofer IPK arbeiten deshalb an Lösungen zum Einsatz von genKI-Modellen, die auf den Einsatz in Unternehmen zugeschnitten sind. Konkret orientiert sich ihre Forschung und Entwicklung an tatsächlichen Fragen und Problemen im unternehmensinternen Wissensmanagement: Wie kann genKI Unternehmen dabei unterstützen, ihren Mitarbeitenden spezifisches Domänenwissen leichter zugänglich zu machen? Wie kann das sicher und unter Wahrung der IP geschehen? Wie lässt sich der Einsatz von genKI in die Unternehmensstrategie einbetten? Und wie kann man schließlich die Mitarbeitenden motivieren, ein KI-basiertes Wissensmanagementsystem gut anzunehmen und auch zu nutzen?
Im Mittelpunkt der FuE-Aktivitäten steht ein Chat-Prototyp, der auf sogenannten Self-hosted Large Language Models (self-hosted LLMs) basiert und als firmeneigener Chatbot auf Fragen oder Anregungen von Mitarbeitenden eigenständig schriftliche Antworten und Inhalte erzeugen kann. Er soll zukünftig ermöglichen, das im Unternehmen vorhandene Wissen leicht zugänglich zu machen. Neben technischen Fragestellungen erforscht das Team von TU Berlin und Fraunhofer IPK auch Aspekte der Organisationsentwicklung wie die kulturelle Akzeptanz und die nötigen Kompetenzen der Beschäftigten, um den Chat-Prototypen zielgerichtet einzusetzen. Ziel ist dabei eine ganzheitliche Lösung, die Technologie- und Organisationsentwicklung verzahnt. So werden genKI-Technologien sinnvoll mit menschlicher Expertise kombiniert, sodass diese als Werkzeuge dienen, die die menschliche Intelligenz ergänzen.
Schutz geistigen Eigentums im Fokus
Im Rahmen des Projekts »ProKI« untersuchen Forschende des IWF der TU Berlin, wie LLMs in Verbindung mit sogenannten Retrieval-Algorithmen genutzt werden können, um Domänenwissen von Unternehmen abzubilden und strukturiert in einem abgeschlossenen und damit geschützten Rahmen für das Unternehmen nutzbar zu machen. Was ChatGPT und Co. in großem Maßstab in Form sogenannter Foundation Models, also sehr großer Wissensmodelle leisten können, lässt sich auch in kleinerer Form gezielt für einzelne Unternehmen erschließen.
Mit self-hosted LLMs können schon verhältnismäßig kleine Datenmengen schriftlich formulierten Wissens, beispielsweise aus technischen Dokumentationen wie Betriebsanleitungen, Wartungsprotokollen, Checklisten oder anderen Quellen des Unternehmens verwendet werden, um eine strukturierte und geschützte Nutzung dieser Wissensbasis zu ermöglichen. Gerade dieses unternehmensspezifische Wissen, das sogenannte Domänenwissen, ist das intellektuelle und somit erfolgskritische Kapital in Firmen. Der wesentliche Vorteil des am IWF entwickelten Prototypen liegt darin, dass der Zugang zu diesem Domänenwissen in seinen vielfältigen Formen nunmehr durch einfache Kommunikation in alltäglicher gesprochener und geschriebener Sprache und sogar in Bildern über den Chatbot erfolgen kann. Durch die self-hosted, also firmenintern gehostete Struktur können organisationsspezifische Anforderungen an Proprietary Information und IP eingehalten werden.
Freundschaften im Vektorraum
Die Forschenden entwickeln unterschiedliche LLM-basierte Chat-Prototypen, durch die Mitarbeitende sicher mit dem domänenspezifischen Wissen interagieren können. Ziel ist es, dass diese Interaktion vollständig innerhalb der Grenzen des lokalen Netzwerks durch den Einsatz von lokal gespeicherten LLMs stattfinden kann. Hierfür werden unterschiedliche Werkzeuge der linguistischen Datenverarbeitung (Natural Language Processing, NLP), einer Fachdisziplin, die sich mit dem Verstehen, der Bearbeitung und der Erzeugung natürlicher Sprache durch Maschinen beschäftigt, in einer Pipeline kombiniert. Diese Pipeline wird als Retrieval Augmented Generation (RAG) bezeichnet und vereint die Stärken von generativer und abfragebasierter KI.
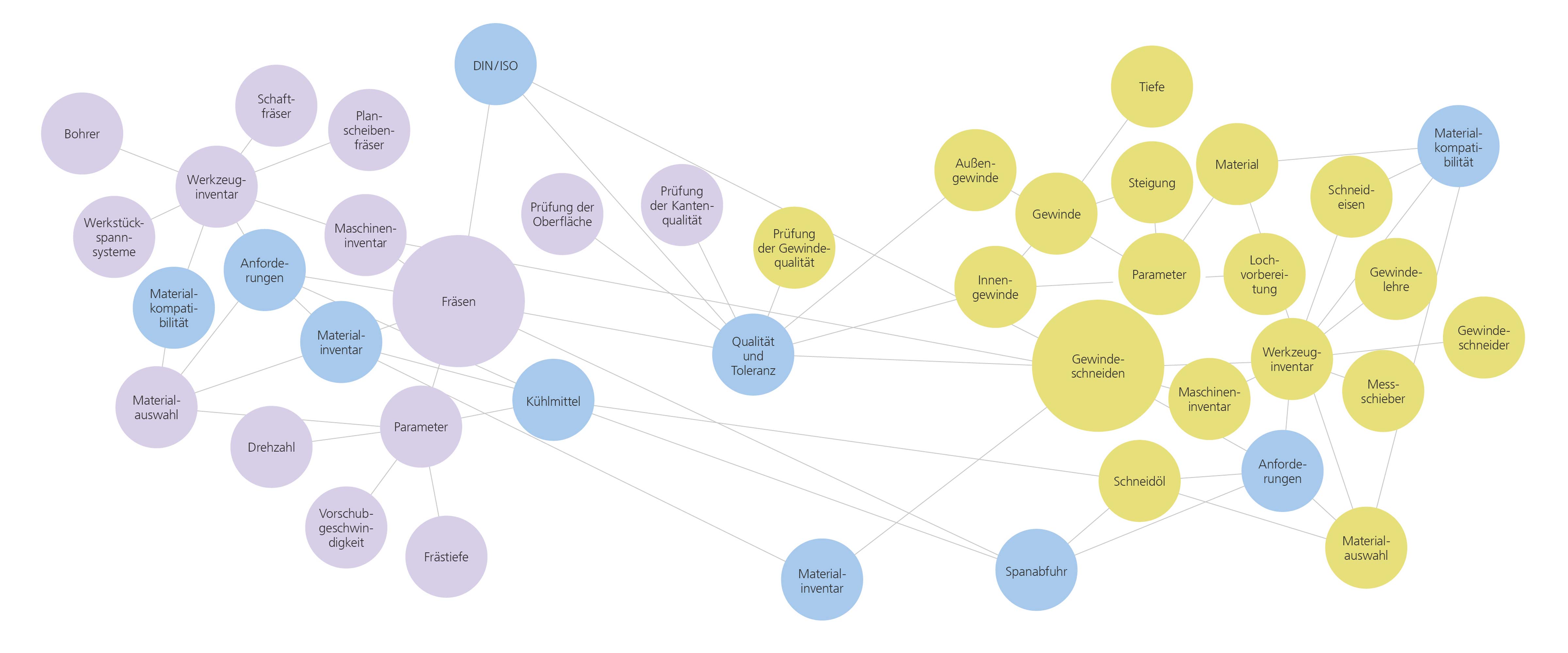
Diese bunte Wolke stellt die verdichtete Datenbasis eines Embedding Models dar – in diesem Fall für den spezifischen Kontext von Bedienungsanleitungen für Fräsmaschinen. Die Grafik verdeutlicht, wie die semantischen Bezüge zwischen den einzelnen Begriffen durch ihre jeweilige räumliche Nähe dargestellt werden. Legende: Begriffe im Bereich Gewindeschneiden sind gelb dargestellt, im Bereich Fräsen violett und Begriffe aus beiden Bereichen blau.
Zunächst erfolgt durch die Methode der Einbettung (embedding) eine verdichtete Informationsdarstellung der semantischen Bedeutung der Datenbasis, also beispielsweise von Bedienungsanleitungen für Fräsmaschinen. Diese Technik repräsentiert die verarbeiteten Texte als dichte Vektoren in einem hochdimensionalen Vektorraum, wodurch ähnliche Inhalte einander näher sind. Dies kann man sich etwa so vorstellen wie in einem sozialen Netzwerk, in dem Wörter oder Phrasen mit anderen Wörtern befreundet sind, wenn sie häufig miteinander interagieren. Wörter und Phrasen mit ähnlichen Bedeutungen oder Verwendungen sind dabei eng miteinander befreundet, etwa »fräsen« und »spanen«. Durch die Erkennung dieser stochastisch-syntaktischen Muster helfen Embedding Models dabei, Wörter und Phrasen später kontextbezogen auf das eingespeiste Domänenwissen einzusetzen. Stellt jemand dem Chat-Prototyp also eine Frage, so wird diese zunächst mithilfe des vortrainierten Embedding Models in den domänenspezifischen Kontext, zum Beispiel den Vektorraum zur Bedienung von Fräsmaschinen, gesetzt. Zuletzt wird ein self-hosted LLM in die Pipeline integriert, das den durch den Abfragealgorithmus gewonnenen Kontext nutzt, um informationsreiche Antworten auf die gestellten Anfragen zu liefern.
Mehr als nur Technologie
Moderne KI-Lösungen eröffnen enorme Potenziale, den systematischen Umgang mit Wissen zu unterstützen, um die Leistungsfähigkeit von Geschäftsprozessen zu optimieren und damit zur Erreichung von Unternehmenszielen beizutragen. Die Erfahrungen der Wissensmanagement-Expertinnen des Fraunhofer IPK zeigen jedoch: Es reicht nicht aus, lediglich eine neue Technologie zur Verfügung zu stellen. Stattdessen ist eine umfassende Betrachtung der gesamten Organisation erforderlich, um die erfolgreiche Implementierung eines KI-basierten Wissensmanagements zu gewährleisten. Unternehmen sollten daher frühzeitig klar definieren, welche Ziele sie im Wissensmanagement mit der Einführung von genKI-Technologien verfolgen möchten. Außerdem müssen die Beschäftigten für den Einsatz von genKI befähigt werden, um die Technologie effektiv anwenden zu können. Neben Kenntnissen zu KI-Grundlagen, Medienkompetenz und technischen Skills wie dem Prompting sind zudem auch ethische und rechtliche Aspekte zu berücksichtigen.
KI kann helfen, aktuelle Herausforderungen im Wissensmanagement wie den Wissenstransfer zwischen den Generationen zu unterstützen. Hierzu gehören beispielsweise ein systematisches Onboarding sowie die gezielte Erfassung und Bewahrung des Erfahrungswissens von langjährigen Expertinnen und Experten beim Ausscheiden aus dem Unternehmen. Hier soll zukünftig der LLM-basierte Chat-Prototyp helfen.
Für neue Mitarbeitende kann der Chat-Prototyp als digitaler Kollege somit eine hervorragende erste Anlaufstelle bei Fragen sein. Durch die Analyse der vielfältigen unternehmenseigenen Datenbasis wird der Chat-Prototyp zudem die richtigen Ansprechpersonen mit Expertise zu konkreten Anliegen identifizieren können und somit auch offline den Wissenstransfer zwischen den Mitarbeitenden fördern.